项目:车辆追踪计数
一.项目介绍
随着城市化进程的加快和交通工具的普及,车辆数量的快速增长给城市交通管理带来了巨大的挑战。车流量检测是交通管理的重要组成部分,它可以提供实时的交通状况信息,帮助交通管理部门制定合理的交通策略,优化交通流量,提高道路利用效率,减少交通拥堵和事故发生的可能性。
传统的车流量检测方法主要依赖于传感器设备,如地磁传感器、红外线传感器等,这些传感器需要在道路上布设,成本较高且安装维护困难。而基于计算机视觉的车流量检测系统则可以通过分析道路上的摄像头图像来实现,具有成本低、安装方便、实时性强等优势。
二.项目任务
本项目通过摄像头拍摄或视频检测图像中的行人,自行车,轿车,货车等种类的车辆,并通过各种方法追踪方法实现对目标的追踪和行驶不同方向的车辆进行计数。总体来说,任务分为两个:检测+追踪
三.项目开展
1.数据集
在群里面问,可能你们不好意思回答的话,我就将标好的数据集给你们,但是,你们必须在开始前熟练掌握标数据的方法,标数据常用的有labelimg,labelme等等,你们可以选择一个喜欢用的标注工具。
链接:标注工具
在这里,我把标好的数据集直接给你们,但是我给你们的数据集不是标准的数据集格式,换句话来说,不是直接能用来训练的数据集,你们需要将标注文件通过自己写脚本将标注数据改为你所需要的格式,常见的有coco格式,yolo格式,voc格式等等,这要看你们所运用的框架,具体你们自己查阅资料。
数据集链接 提取码:7tdw
在这里我说一下我给你们的数据集的标注文件格式,里面有一些对于某些框架是没有用的,需要做些处理。
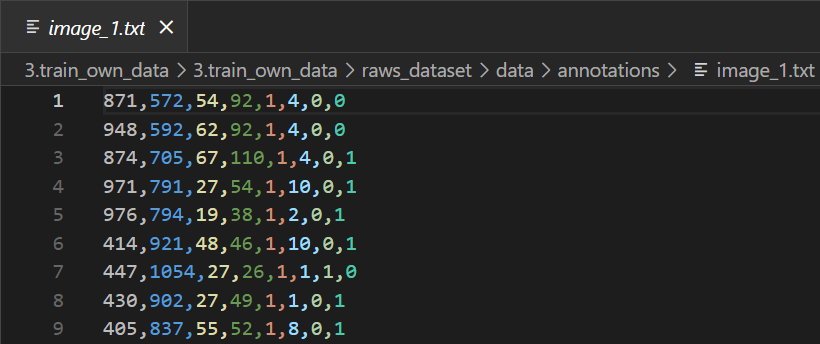
1
2
3
4
5
6
7
8
9
|
<bbox_left>,<bbox_top>,<bbox_width>,<bbox_height>,<score>,<object_category>,<truncation>,<occlusion>
即:左上角坐标,宽,高,置信度,类别,截断,遮挡
原数据集的类别对应:name_dict = {'0': 'ignored regions', '1': 'pedestrian', '2': 'people',
'3': 'bicycle', '4': 'car', '5': 'van', '6': 'truck',
'7': 'tricycle', '8': 'awning-tricycle', '9': 'bus',
'10': 'motor', '11': 'others'}
其中'0': 'ignored regions'和'11': 'others'用于标记那些不属于另外主要10个类别中的任何一个的对象或背景,有个好处就是可以处理数据集中的异常情况,确保每个检测到的对象都能被分类,确保稳定性,当然我们这个就不太需要,大家只需要把这两个忽略掉就可以了,提取所需信息,删除无用信息
|
2.数据增强(可选)
数据增强也就是通过某些手段对改变原有数据增加数据量,例如模拟光线增强,高斯模糊,椒盐噪声,HSV色调改变等等,可以自己通过之前学的OpenCV写脚本,这里我推荐一款好用的可视化数据增强软件,所支持的增强类型还是挺多的,不过需要学习一下怎么用,还是比较容易上手的。
链接:数据增强软件
3.数据划分
我给你们的数据集是总体的,但是训练需要将数据划分为训练集和验证集,才能进行训练,你们需要自行写脚本将数据划分,这里我推荐利用K折交叉验证的方法对数据进行划分,你们可以了解了解该原理。
链接:K折交叉验证原理
4.训练框架
你们可以选择任意一种框架,RCNN,Faster-RCNN,SSD和YOLO系列神经网络模型,这里不做要求。但是无论你们选择哪一种框架,你们需要找出代码的核心,也就是网络搭建的过程并指出。
当然如果你们学习算法已经足够实现搭建自己的网络的技术,你们也可以选择自己的框架,或者是通过对现有网络自己进行剪枝和量化等操作进行训练,当然这个肯定是个非常大的加分项。
5.训练过程
你们可以选择在自己电脑上进行训练,也可以在网上租用算力进行训练,可以在Windows系统上训练也可以,在Linux系统上进行训练,这个不做要求。
6.模型推理
在训练结束后,你将会得到一个最优的权重,这个也就是你选用模型对验证集推理与事实结果相差最小的一个权重,里面保存了各个参数具体的值。
模型推理也就是利用训练出的最优的这个权重,对图片进行检测后得到的结果。而推理框架具有许多种,这里我举YOLOV8为例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| yolo mode=val model=yolov8n.pt
yolov8n.torchscript
yolov8n.onnx
yolov8n_openvino_model
yolov8n.engine
yolov8n.mlpackage
yolov8n_saved_model
yolov8n.pb
yolov8n.tflite
yolov8n_edgetpu.tflite
yolov8n_paddle_model
yolov8n_ncnn_model
.pt也就是你用pytorch框架训练得到的参数文件
.onnx模型是比较通用的一种模型文件,可以利用OpenCV的DNN模块进行推理
.engine文件(也可以是trt)文件,可以利用nvidia的gpu(通用计算平台)进行推理(可以大大提高推理速度)
.openvino文件可以通过intel的cpu进行推理,也可以大大推高推理速度等等
|
模型推理可以选择训练本身的框架进行推理,也可以选择以上加速框架(tensorrt、dnn、onnxruntime、openvino、tflite、ncnn等等框架),并非是pytorch-gpu,tensorflow-gpu或者是paddlepaddle-gpu,如果选择另外一种加速框架,肯定会有加分。
7.封装成类
(1)格式与要求
封装成类的格式和要求,最少需要以下函数,这里我以python为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| class Person_Vehicle_tracking_count():
def __init__(self,model_path,classes_path):
'''
__init__方法为定义一些类的模型参数,类别参数,nms最大抑制值和IOU追踪参数等等所需参数
'''
def img_detect(self,img_path):
'''
img_detect方法传入参数是图片路径
返回并打印result,最好在图片中用putText函数显示,格式是
[use_time,[id_1,score_1,x1_1,y1_1,x2_1,y2_1],
[id_2,score_2,x1_2,y1_2,x2_2,y2_2]......]
use_time是推理该张图片所用的时间
id_1是第一个框对应的类别
soore_1是第一个框的对应的置信度
x1_1是第一个框对应的左上角x值
y1_1是第一个框对应的左上角y值
x2_1是第一个框对应的右下角x值
y2_1是第一个框对应的右下角y值
以此类推
'''
return result
def map_calculation(self,jpg_folder_path,xml_folder_path):
'''
方法map_calculation,传入的参数有两个,
一个是jpg图片的文件夹地址,另一个是xml标注文件的文件夹地址
计算出map,返回并打印map
map的值是ap50:95的平均值
可以在网上寻找利用具体公式进行计算,也可以利用pycocotools的公式进行计算
'''
return map
def img_count(self,img_path):
'''
img_count方法传入参数是图片路径
返回并打印result值为统计该图片每个类的数量,最好在图片中用putText函数显示,格式为
{'pedestrian':num0,'people':num1,'bicycle':num2,
'car':num3,'van':num4,'truck':num5,'tricycle':num6,
'awning-tricycle':num7,'bus':num8,'motor':num9}
'''
return result
def video_detect(self,video_path):
'''
video_detect方法传入参数是视频路径
返回并打印result,格式是视频最终经过某条路一个方向与相反一个方向的每种类别的数量,并在视频显示时实时显示数量的增加
例如加入你指定正方向为朝上,那么第一个集合为记录行人和车辆向上行驶的数量,第二个集合为记录行人和车辆向上下行驶的数量
追踪方法我这里举几个方法,自行查阅:IOU,卡尔曼滤波、botsort、bytetrack
result格式为
[{'pedestrian':num0,'people':num1,'bicycle':num2,'car':num3,'van':num4,
'truck':num5,'tricycle':num6,'awning-tricycle':num7,'bus':num8,'motor':num9},
{'pedestrian':num0,'people':num1,'bicycle':num2,'car':num3,'van':num4,
'truck':num5,'tricycle':num6,'awning-tricycle':num7,'bus':num8,'motor':num9}]
'''
return result
|
video_detect方法具体效果如以下视频所示:
视频链接 提取码:1yxo
(2)推理系统和语言
推理系统不限于Windows,Linux(虚拟机也算),Mac,语言不限于python,C++
推理系统若使用Linux系统进行推理和若使用C++语言进行推理也会有相应的加分。
四.模型部署于开发板(可选)
训练模型最终的目的肯定是落地于实践,有开发板的同学,不限制使用的芯片框架,X86,ARM,RISC-V或者是龙芯框架,例如树莓派、香橙派、Jetson系列
五.评分细则
1.完成数据集的整理并训练出最优权重 +30
2.成功定义类和img_detect方法完成模型推理 +20
3.成功定义map_calculation方法并计算出map值 +20
4.成功定义img_count方法并计算出result值 +20
5.成功定义video_detect方法并实现实时追踪和计数功能 +30
6.观察模型准确性和视频实时推理帧率,效果优秀 +20
7.使用以上所说的一种加速框架进行模型推理 +20
8.使用Linux系统实现模型推理 +20
9.使用C++语言实现类和方法的定义 +20
10.将模型部署于开发板,并成功运行实现模型推理 +20
11.使用QT四个方法写成有的界面效果展示 +20
六.任务提交
1.线上
时间:开学前即可
提交:提交项目所有实现代码和脚本和测试视频,提交项目完成报告,不限于在完成项目中遇到的困难和解决方法、在完成项目中实现的逻辑和学习到的知识
2.线下
时间:开学后,具体时间暂定
现场进行对项目的介绍和演示,并根据现场演示情况进行打分
__END__
